
SMS are not 160 characters long, they are 140 bytes long! This is what I discovered today after my SO complained that her mobile operator was charging her for SMS she never sent…
And when you know how computers are working, it totally makes sense!
“So what?” are you going to ask? So, this is again a nice example of character encodings drive you crazy. According to wikipedia there are 3 encodings used in text messages which respectively use 7bits, 8bits and 16bits to encode a single character.
Depending on the characters you used in your message your phone is going to decide what encoding to use, thus reducing the maximum number of characters to, respectively, 160, 140 and 70 (and even less, see later). Any extra character will lead to the splitting of your message into multiple SMS and, obviously, a raise in your bill.
By default the 7bit encoding used is GSM 03.38, which has the following 128 characters alphabet: @, £, $, Â¥, è, é, ù, ì, ò, Ç, LF, Ø, ø, CR, Ã…, Ã¥, Δ, _, Φ, Γ, Λ, Ω, Î , Ψ, Σ, Θ, Ξ, ESC, Æ, æ, ß, É, SP, !, “, #, ¤, {5f676304cfd4ae2259631a2f5a3ea815e87ae216a7b910a3d060a7b08502a4b2}, &, ‘, (, ), *, +, ,, -, ., /, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, :, ;, <, =, >, ?, ¡, A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, Ä, Ö, Ñ, Ãœ, §, ¿, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, ä, ö, ñ, ü, Ã
If you use only those characters, then you text messages can have 160 characters, however, any character outside of this alphabet will mean the use of a different encoding. And if you are using exotic scripts, your messages will be encoded in UTF-16Â and in this encoding a Chinese character, for example, will take up to 4 bytes, reducing the maximum length of you Chinese message to 35 characters max.
I guess that now that smart phones are supporting international scripts and transparently breaking up text messages, a lot of people get trapped. The only recommendation I can think of is to enable your phone to display the character count when you type text messages, I noticed that my iPhone is changing the maximum number of characters according to the encoding it’s going to use to send my message.
If you want to know more about character encodings I absolutely recommend the following article by Joel Spolsky: The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
UPDATE: At Stephanie’s request here is how to activate message count on your iPhone (at least on my 3GS with iOS 4.1).
Go to your iPhone settings, scroll down to “Messages” then toggle “Character Count” on. When you write a text message the count will show up only if you have at least two lines of text :)
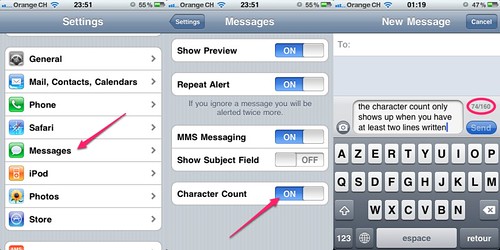
Image Credits: Steve Webel
 When you have a problem with your car and you go to the garage you usually say something along the line of “I’ve got a strange noise when I do this or that”. The guy (or, in my dreams, the gal) never say “I don’t understand, come back later with a better description of your problem”.
When you have a problem with your car and you go to the garage you usually say something along the line of “I’ve got a strange noise when I do this or that”. The guy (or, in my dreams, the gal) never say “I don’t understand, come back later with a better description of your problem”. Here is a small snippet of code that I use on applications deployed on Google AppEngine to inform users that the application is in maintenance mode.
Here is a small snippet of code that I use on applications deployed on Google AppEngine to inform users that the application is in maintenance mode. 
 For those of you who were at the Lift conference 2008 you might remember of
For those of you who were at the Lift conference 2008 you might remember of 